Optimizing Refraction for Raytracing
Introduction
For those of you holding off on implementing 3D refraction in your raytracer, the time has come to start coding it! Why? Because refraction looks cool and can be as simple and easy as 7 multiplications, 5 additions, and one table look up. That's almost as simple as 3D reflection, which takes 7 multiplications and 5 additions.
Here's a quick refresher lesson on refraction.
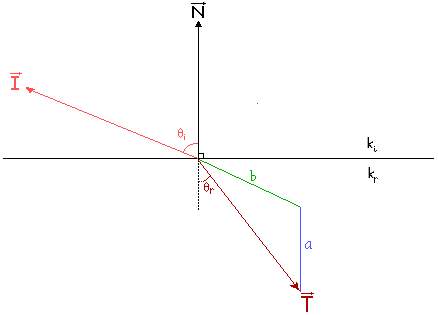
Merriam Webster's dictionary describes refraction as "deflection from a straight path undergone by a light ray or energy wave in passing obliquely from one medium (as air) into another (as glass) in which its velocity is different." Basically, it's the bending of light through lenses, water, etc. Mathematically, the amount the light bends can be described by Snell's Law. It says the relationship between the angle of incidence theta_i and the angle of refraction theta_r, is
sin(theta_i) kr
------------- = --------
sin(theta_r) ki
where ki is the index of refraction of the material on the incident side, and kr is the index of refraction of the transmitting medium on the refractive side. These indices of refraction are always >= 1.0. A typical index of refraction ranges from 1.0 (vacuum) to 1.6 (some crystals). The more the ratio kr/ki differs from 1.0, the more the passing light bends when traveling through the interface. Although we won't worry about this, the index of refraction is also dependent on the light's wavelength; that's how prisms work.
The Math
Snell's Law is deceptively simple compared to deriving the actual refraction vector equation. The derivations involve a lot of linear algebra and geometry. But you don't really need this math to enjoy the benefits of 7 mul refraction. You can safely skip this section, and start look at the code following it.
First some definitions. The incident vector I is defined to be unit vector that points backwards from the light ray's point of collision back toward its source. The normal vector vector N is a unit vector perpendicular to the plane that separates the incident and refracted media, and points toward the incident side. The refracted vector T is another unit vector that shoots outward from the collision point between the two media. The number b is the ratio of refraction coefficients.
One derivation for refraction vector calculation is in the book "Computer Graphics: Principle and Practice" by Foley et. al. on pages 757-758. The derivation is based on finding a unit vector M that is in the plane formed by the vectors N and I, and is also perpendicular to N, and showing the refracted vector T = sin(theta_t)*M - cos(theta_t)*N, and using substitution and the Pythagorean theorem to find the surface normal vector scale factor with magnitude "a."
There is a different derivation which results in the same equation, found in the raytracer source code at www.relisoft.com.[1] It uses the properties of the refracted vector (like T.T = 1 and the cross product of T with N and N with I is the same vector) and solves a quadratic equation using the quadratic formula. The method also differs from the previous one in that it directly seeks a coefficient "a" that fits the form T = -a*N - b*I.
Unoptimized Code For Refraction
The refraction vector T is normally calculated as
T = (b * (N.I) -/+ sqrt(1 - b^2*(1-(N.I)^2))*N - b*I
where N.I = cos(theta_i), sqrt(1 - b^2*(1-(N.I)^2)) = cos(theta_t) and b=ki/kr or kr/ki depending on whether the light is coming from above or below the surface. I'm using vector arithmetic notation here, and using ^2 to represent squares of a number. The -/+ means use minus when ndoti>=0, and use plus otherwise.
Implemented as code, this takes a whopping 12 muls or more!
vector* RefractSlow(vector N, vector I)
{
float ndoti, two_ndoti, ndoti2, a,b,b2,D2;
vector* T=new vector();
ndoti = N.x*I.x + N.y*I.y + N.z*I.z; // 3 mul, 2 add
ndoti2 = ndoti*ndoti; // 1 mul
if (ndoti>=0.0) { b=r; b2=r2;} else {b=invr;b2=invr2;}
D2 = 1.0f - b2*(1.0f - ndoti2);
if (D2>=0.0f) {
if (ndoti >= 0.0f)
a = b * ndoti - sqrtf(D2); // 2 mul, 3 add, 1 sqrt
else
a = b * ndoti + sqrtf(D2);
T->x = a*N.x - b*I.x; // 6 mul, 3 add
T->y = a*N.y - b*I.y; // ----totals---------
T->z = a*N.z - b*I.z; // 12 mul, 8 add, 1 sqrt!
} else {
// total internal reflection
// this usually doesn't happen, so I don't count it.
two_ndoti = ndoti + ndoti; // +1 add
T->x = two_ndoti * N.x - I.x; // +3 adds, +3 muls
T->y = two_ndoti * N.y - I.y;
T->z = two_ndoti * N.z - I.z;
}
return T;
}
But we can optimize this to perform much less arithmetic by calculating common stuff in a lookup table! Check out the code below comparing optimized reflection to optimized refraction.
Optimized Reflection and Refraction Code
int scalefac = 16384;
const float TIRflag = -999.0f;
float *aLUT, *LUTBuf; // global lookup table
float ki=1.0f, kr=1.333f; // for air and water
float r=ki/kr, r2=r*r;
float invr=kr/ki, invr2=invr*invr;
struct vector { float x,y,z; };
vector* Reflect(vector N, vector I)
{
vector* R = new vector();
float two_ndoti;
// ------REFLECTION----------------------- //
// New vector R = reflection of I about N.
two_ndoti = 2 * (N.x * I.x + N.y * I.y + N.z * I.z); // 4 muls, 2 adds
R->x = two_ndoti * N.x - I.x; // 3 muls, 3 adds
R->y = two_ndoti * N.y - I.y; // --total-------
R->z = two_ndoti * N.z - I.z; // 7 muls, 5 adds
return R;
}
vector* RefractFast(vector N, vector I)
{
vector* T = new vector();
float b,a,two_ndoti,ndoti;
// ------REFRACTION----------------------- //
// New vector T = refraction of I through surface with normal N.
// assumes r = ki/kr and invr = kr/ki are known constants.
ndoti = N.x * I.x + N.y * I.y + N.z * I.z; // 3 muls, 2 adds
if (ndoti>=0.0) b=r; else b=invr;
// The "a" variable here is a floating point quanity that
// equals the surface normal vector scale factor.
a = aLUT[(int)(ndoti*scalefac)]; // 1 mul, 1 lookup
if (a != TIRflag)
{
T->x = a*N.x - b*I.x; // 6 muls, 3 adds
T->y = a*N.y - b*I.y; // --total------------
T->z = a*N.z - b*I.z; // total: 10 muls, 5 adds,
} else { // 1 lookup
// total internal reflection
// this usually doesn't happen, so I don't count it.
two_ndoti = ndoti + ndoti; // +1 add
T->x = two_ndoti * N.x - I.x; // +3 adds, +3 muls
T->y = two_ndoti * N.y - I.y;
T->z = two_ndoti * N.z - I.z;
}
return T;
}
That's not 7 muls, you might've noticed. I'm not lying about the possibility -- keep reading to find out how to get the code down to 7 muls.
The "a" coefficient lookup table (aLUT[]) calculates the normal vector scalefactor for as many ndoti (cosine of the angle of incidence) as necessary. Math geeks may object to using lookup tables since they only offer a sampled view of the normal vector scalefactor (stored in variable "a"), but to a demo coder, accuracy doesn't matter as much as speed. Further, you can make the lookup table as large as your accuracy demands for by increasing "scalefac."
Precalculating aLUT[]
Here's the code to precalculate the table.
// INPUTS:
// ki is the coefficient of refraction of the material on the incident side
// of the interface
// kr is the coefficient of refraction of the material on the refracted side
// of the interface
// OUTPUTS:
// aLUT[], an initialized lookup table containing the 'a' coefficient.
void precalcTable(float ki, float kr)
{
int z;
float ndoti,ndoti2, b, b2,D,D2;
LUTBuf = new float[scalefac*2+1];
aLUT = LUTBuf + scalefac;
// z corresponds to a fixed point ndoti (or angle between
// incident and normal rays)
// note that floating point dot product ranges from -1.0 to +1.0,
// while the fixed point one ranges from -scalefac to scalefac.
for (z=-scalefac; z<=scalefac; z++)
{
ndoti = (float)z / (float)scalefac;
if (ndoti >= 0.0) {
//entering vacuum from object
b = r;
b2 = r2;
}else{
//entering object from vacuum
b = invr;
b2 = invr2;
}
ndoti2 = ndoti * ndoti;
D2 = 1.0f + b2 * (ndoti2 - 1.0f);
if (D2 >= 0.0) {
D = sqrtf(D2);
if (ndoti >= 0)
aLUT[z] = -(-b * ndoti + D);
else
aLUT[z] = -(-b * ndoti - D);
}else{
// total internal reflection
aLUT[z] = TIRflag;
}
}
}
Optimizing The Unnormalized Vector Case
It is possible to optimize this refraction function further, if we loosen one constraint, that is the refracted vector must be normalized. This is the case for many raytracers out there, as is for simplified caustics calculation. Then you can get rid of the multiplication of the I (incident) vector by b. This saves 3 multiplications. So, that means we can do 3D refraction in 7 muls and 5 adds. I hope you realize this is big improvement over the conventional refraction algorithm with 12 muls.
vector* Refract_Unnormalized(vector N, vector I)
{
vector* T = new vector();
float a,two_ndoti,ndoti;
// ------REFRACTION----------------------- //
// New vector T = refraction of I through surface with normal N.
// assumes r = ki/kr and invr = kr/ki are known constants.
ndoti = N.x * I.x + N.y * I.y + N.z * I.z; // 3 muls, 2 adds
/// ---begin changes---------------=========
g = gLUT[(int)(ndoti*scalefac)]; // 1 mul
if (g != TIRflag)
{
T->x = g*N.x - I.x; // 3 muls, 3 adds
T->y = g*N.y - I.y; // --total------------
T->z = g*N.z - I.z; // total: 7 muls, 5 adds, 1 lookup
/// ---end changes -----------------========
} else {
// total internal reflection
// this usually doesn't happen, so I don't count it.
two_ndoti = ndoti + ndoti; // +1 add
T->x = two_ndoti * N.x - I.x; // +3 adds, +3 muls
T->y = two_ndoti * N.y - I.y;
T->z = two_ndoti * N.z - I.z;
}
return T;
}
gLUT[] just contains the values of aLUT[] scaled by (1/b), unless total internal reflection is detected, in which case, TIRflag is stored. The reason this works is because the new T vector, which I'll call T', is equal to the old T vector scaled by 1/b.
More Restricted Special Cases
For 2D refraction, you can precalculate the refracted vectors themselves instead of the the surface normal vector scale factor. That will reduce the function to something like:
ndoti = N.x * I.x + N.y * I.y; // 2 muls, 1 add
fixedpt_ndoti = (int)(scalefac*ndoti); // 1 mul
*T = RefractVecLUT[fixedpt_ndoti]; // --totals:--------
// 3 mul, 1 add, 1 lookup
excluding the code to handle the special case for total internal reflection.
For further speedups over my method, assembly hackers may think of a clever way to get rid of the scalefactor multiplication by treating a float directly as a series of bits representing an integer index, as using some of these bits to index the lookup table.
If you don't mind the errors introduced by cruder approximations, Gustavo[2,3] presents an approximation to refraction by effectively using a one-element lookup table for "a." The optimal value to use for the approximation of "a" is probably the "a" function's average value. In that case, you don't really need to multiply the ndoti by the scalefactor, because the approximation of "a" is independent of the incident angle. Also, you don't need to perform the dot product anymore. In total, this approximation saves four multiplications over my two methods.
Conclusion
Now you don't have to complain that refraction is too slow or too difficult to use in realtime raytracing. You have the algorithm and understanding needed for speeding up refraction calculations using lookup tables and algebraic simplification.
The mathematical derivations may have been a bit light on the details, to allow you to get to the code quicker. If you need more explanations to feel confident that the code works, email me, and I'll be happy to explain it further. If you find any bugs in my code, please report it. Also, if you know how to or are interested in doing realtime caustics that look as good as [4], let me know.
Greets to EvilGeek (Tor Myklebust), whose conversation got me thinking into optimizing refraction code, and entropy (Tyler Spaulding), who implemented the first realtime caustics demo for QB, and came up with the optimization for the unnormalized refraction vector case.
References
1. Relisoft, "Java raytracer source" http://www.relisoft.com/Web/java.zip
2. Oliveira, Gustavo, "Refractive Texture Mapping, Part 1"
http://www.gamasutra.com/features/20001110/oliveira_01.htm
3. Oliveira, Gustavo, "Refractive Texture Mapping, Part 2"
http://www.gamasutra.com/features/20001117/oliveira_01.htm
4. Ng, Yi-Ren, "Pond Caustics", http://www.stanford.edu/~yirn/cs348b/